
Ever wondered how Google discovers your website? It’s through a process called crawling in SEO – the critical first step that determines whether your content even has a chance to rank. Without effective crawling, your brilliant content might remain invisible to search engines, no matter how well-optimized it is.
Crawling serves as the foundation of search engine visibility. It’s like opening the front door to invite Google in to see what you’ve created. Let’s dive into how this process works and why getting it right can make or break your SEO success.
Understand How Crawling Works in SEO
What does a crawler do exactly
Search engine crawlers (also called spiders or bots) are automated programs that systematically browse the web. Think of them as digital explorers that follow links to discover content. When a crawler visits your site, it:
- Discovers your pages by following links
- Downloads your page content
- Analyzes the HTML structure and content
- Follows additional links to find more pages
- Reports back to the search engine database
GoogleBot, Bing’s crawler, and other search bots are constantly in motion, visiting billions of websites. They’re like scouts who need to efficiently explore the vastness of the internet.
Crawling vs indexing in SEO
People often mix these up, but they’re distinct processes:
| Crawling | The discovery process where bots find and scan your pages |
| Indexing | The storage and organization of page content in the search engine’s database |
Just because a page is crawled doesn’t guarantee indexing. Google might crawl your page but decide it’s not worthy of indexing due to quality issues, duplicate content, or relevance problems.
Key SEO crawling tools
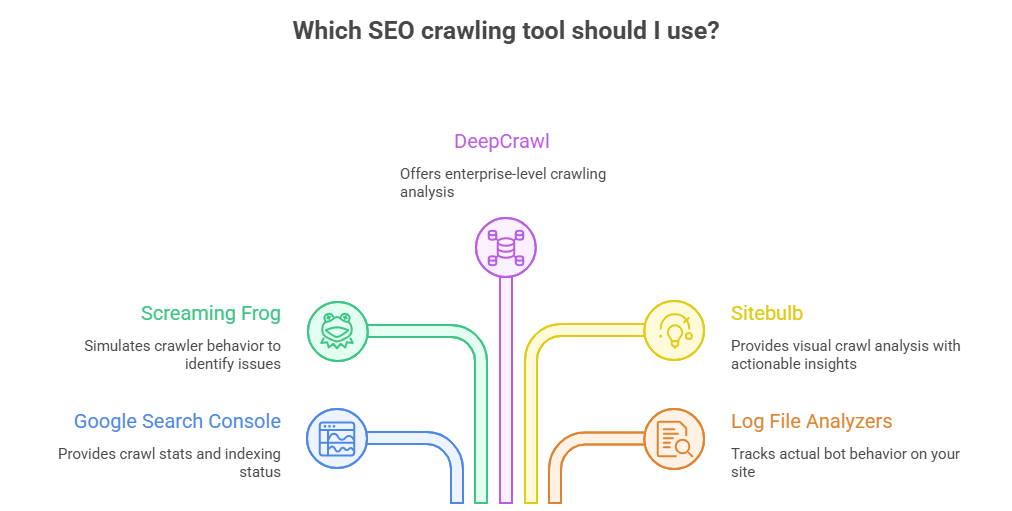
Several tools can help you monitor and improve crawling:
- Google Search Console: Shows crawl stats, errors, and indexing status
- Screaming Frog: Simulates crawler behavior to identify issues
- DeepCrawl: Enterprise-level crawling analysis
- Sitebulb: Visual crawl analysis with actionable insights
- Log file analyzers: Track actual bot behavior on your site
These tools help you see your website through a crawler’s eyes, spotting problems before they hurt your rankings.
Improve Crawl Budget and Indexing
Reduce waste through crawl budget optimization
Every website has a limited “crawl budget” – the number of pages search engines will crawl in a given time period. Don’t waste it on unimportant content!
Smart optimization tactics include:
- Creating logical site architecture with shallow click depth
- Using robots.txt to block low-value pages
- Implementing a clean XML sitemap
- Fixing redirect chains that waste crawl resources
- Removing duplicate content that divides crawl attention
Fix crawl errors from server logs
Server logs reveal the truth about how bots interact with your site. Common crawl errors to fix include:
- 404 errors: Pages that don’t exist but are still linked
- 500 errors: Server-side problems blocking crawlers
- Timeout issues: Slow-loading pages that frustrate bots
- Soft 404s: Pages that return 200 status but show error content
Regularly check and fix these issues to keep crawlers happy and efficient.
Prioritize pages for fast indexing in SEO
Not all pages deserve equal crawling attention. Help search engines focus on your most important content by:
- Linking directly to key pages from your homepage
- Using internal linking strategically
- Implementing priority URLs in your XML sitemap
- Using the URL Inspection tool in Google Search Console to request indexing
- Building quality backlinks to critical pages
Why Technical Crawling Signals Impact SEO Rankings
Crawling efficiency directly impacts your SEO success. When search engines can easily discover, access, and understand your content, you’re setting the stage for better rankings.
Sites with crawl problems face an uphill battle. No matter how amazing your content or backlink profile, if search engines struggle to crawl your site, your visibility will suffer.
Plus, Google interprets crawl efficiency as a quality signal. Sites that waste crawl resources with broken links, redirect chains, or confusing architecture send negative signals about their overall quality.
The bottom line? Mastering the technical aspects of crawling gives you a competitive edge that many SEO strategies overlook.
FAQs
What factors affect crawl budget in SEO?
Your site’s crawl budget is influenced by site size, page speed, server capacity, update frequency, and domain authority. Larger, more authoritative sites typically get more generous crawl budgets. Technical factors like site speed and server response time also play major roles – faster sites get crawled more efficiently.
How often do search engine bots crawl my website?
It varies widely based on your site’s authority, update frequency, and size. Popular, regularly-updated sites might get crawled multiple times daily, while smaller, static sites might only see crawlers weekly or monthly. Check Google Search Console’s crawl stats report for your specific data.
Which SEO crawling tools are most effective in 2025?
The most valuable tools continue to be Google Search Console (for official crawl data), Screaming Frog (for detailed technical audits), Sitebulb (for visual analysis), and DeepCrawl (for enterprise sites). New AI-enhanced crawling tools are also emerging that predict crawl patterns and automate optimization.
Can I block search engine bots from crawling my website?
Yes, through robots.txt files, meta robots tags, or password protection. However, blocking crawlers means blocking indexing and visibility. It’s better to use targeted blocking for specific low-value pages rather than preventing crawling entirely unless you have a good reason to stay out of search results.

Ridam Khare is an SEO strategist with 7+ years of experience specializing in AI-driven content creation. He helps businesses scale high-quality blogs that rank, engage, and convert.


